acurácia com K-NN Euclidiana e Chebyshev
Apresentação editorial · IA, notas falsas e DevSecOps
Um deck pensado para ser lido na web, anexado em PDF e usado como base de conversa técnica em ambientes corporativos e acadêmicos.
acurácia com Naive Bayes Multivariado
ganho de velocidade do Naive Bayes sobre K-NN Euclidiana
amostras no dataset de autenticação de notas
Base institucional
UNIFOR · Universidade de Fortaleza
Disciplina de Inteligência Artificial
Pesquisa acadêmica com desdobramento corporativo e editorial pela Líder Projetos

Um mapa de leitura para entender o relatório com rapidez.
Em vez de uma página longa, o conteúdo foi reorganizado como capítulos de apresentação, cada um com função clara dentro da história técnica.
Detectar fraude com rigor estatístico é uma conversa sobre confiança operacional.
1.372 amostras com quatro features estatísticas extraídas via Transformada Wavelet.
Cinco classificadores construídos do zero para comparar precisão, custo e comportamento.
O resultado só ganha valor quando é reproduzível, comparável e auditável.
K-NN dominou a precisão, mas o Naive Bayes Multivariado mudou a conversa sobre escala.
Velocidade também é arquitetura: o melhor modelo depende do cenário de uso.
A diferença entre os dois Naive Bayes mostra por que correlação não é detalhe.
A pergunta correta não é qual algoritmo ganhou. É qual compromisso faz sentido para a operação.
Quando a prioridade é precisão máxima, o K-NN mostra toda a sua força.
Quando velocidade, previsibilidade e escala entram forte na mesa, o Bayes muda o jogo.
O mesmo relatório permite decidir qual abordagem cabe melhor em cada tipo de fluxo.
Os números importam, mas o principal valor está na disciplina do método.
O experimento com notas falsas vira uma tese prática sobre governança de IA.
O mesmo risco de superajuste que existe em modelos clássicos reaparece em prompts e agentes.
Generalização não nasce de intuição. Ela nasce de equilíbrio e teste.
Prompt com boa aparência ainda não é prova de robustez.
O que um pipeline sério de avaliação precisa ter antes de homologar IA para produção.
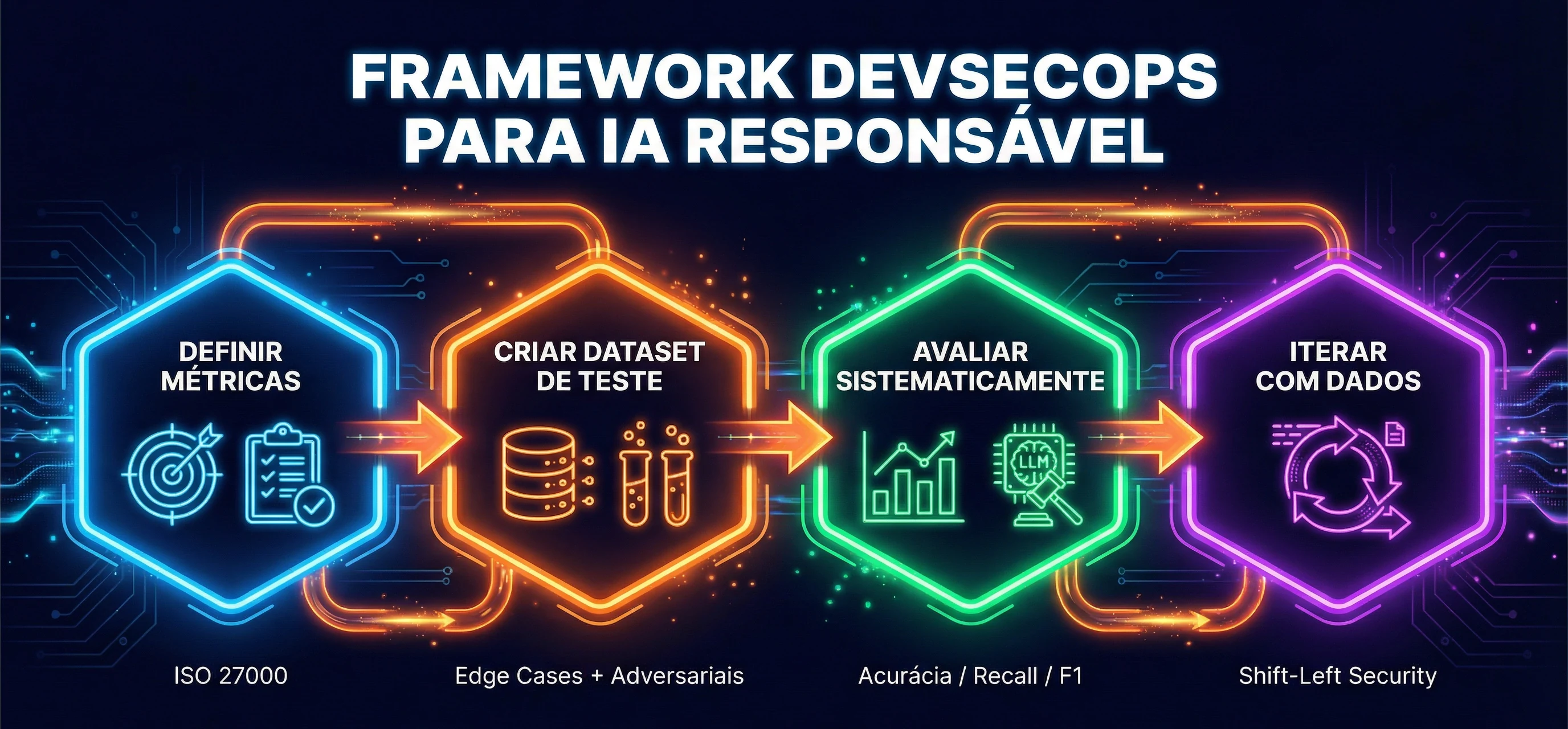
01
Definir métricas
- acurácia factual
- aderência ao formato
- segurança e conformidade
02
Criar dataset
- casos comuns
- edge cases
- cenários adversariais
03
Automatizar avaliação
- testes sistemáticos
- comparação entre versões
- observabilidade
04
Iterar com governança
- ajuste
- reteste
- versionamento
- documentação